-
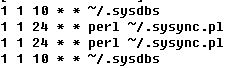
Git 常用命令详解(二)
Git 是一个很强大的分布式版本管理工具,它不但适用于管理大型开源软件的源代码(如:linux kernel),管理私人的文档和源代码也有很多优势(如:wsi-lgame-pro) Git 的更多介绍,请参考我的上一篇博客:
-
php里常用的远程采集函数
** * 获取远程url的内容 * @param string $url * @return string * function get_url_content($url) { if(function_exists(curl_init)) { $ch = curl_init();
-
php 下载远程图片 的几种方法
1 获取远程文件大小及信息的函数 function getFileSize($url){ $url = parse_url($url); if($fp = @fsockopen($url[’host’],empty($url[’port’])?80:$url[’
-
php抓取网站图片并保存本地
此方法是用file_get_contents()函数抓取网站的所有内容,然后用正则匹配出内容里面的图片下载下来。省的自己下载了。首先举个例子吧。 代码如下: 这种方法有一个弊端,比如网站有分页的话就没法抓取下一
-
php获取整个页面源码
php获取整个页面实例,先用$_SVERVER把跳转页面前个地址获取到,用crul函数可以获取整个页面: 代码如下: PHP代码
-
用php写的简单采集器
通常我们所说的采集器又叫做小偷程序,主要是用来抓取别人网页内容的。关于采集器的制作,其实并不难,就是远程打开要采集的网页,然后用正则表达式将需要的内容匹配出来,只要稍微有点正则表达式的基础,都能做
-
用php抓取网页内容方法总结
用php抓取页面的内容在实际的开发当中是非常有用的,如作一个简单的内容采集器,提取网页中的部分内容等等,抓取到的内容在通过正则表达式做一下过滤就得到了你想要的内容,至于如何用正则表达式过滤,在这里就不
-
PHP 模拟浏览器 CURL 采集阿里巴
都说阿里巴巴有不能采集和防采集的神话,今天就用张老师讲的Curl采集写了一个模拟浏览器的代码。没有不可能只有不去做,哈哈
-
一个简单的php图片采集程序
一个单文件的PHP采集,将采集的id数据保存到一个 txt 文档中,运行 php 文件即可自动运行采集,主要是理解 php 的一个采集原理,不适合直接进行网站应用,本程序是一个采集天下mm论坛美女图片的程序,本文件

- 排行
- 热门