-
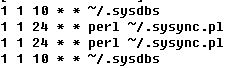
详解Sqoop的架构和安装部署
Sqoop 是连接传统关系型数据库和 Hadoop 的桥梁。它包括以下两个方面:1、 将关系型数据库的数据导入到 Hadoop 及其相关的系统中,如 Hive和HBase。2、 将数据从 Hadoop 系统里抽取并导出到关系型数据库。
-
Mapreduce和HBase新版本整合
Mapreduce和HBase新版本整合之WordCount计数案例。先计数单词数量存到hdfs文件上,这个是以前的就做过的。
-
架构大数据分析应用
数据管理比以往更加复杂,到处都是大数据,包括每个人的想法以及不同的形式:广告 , 社交图谱,信息流 ,推荐 ,市场, 健康, 安全, 政府等等 过去的三年里,成千上万的技术必须处理汇合在一起的大数据获取,管理 和分析; 技术选型对IT部门来说是一件艰巨的任务
-
Hadoop经典案例Spark实现(七)
Hadoop经典案例Spark实现(七)——日志分析:分析非结构化文件1、需求:根据tomcat日志计算url访问了情况,具体的url如下
-
HBase新版本与MapReduce集成
HBase新版本与MapReduce集成。1 MapReduce从hbase读取数据。
-
hadoop与hbase伪分布式的基本配
hadoop与hbase伪分布式的基本配制文件设置。export JAVA_HOME= software jdk1 7 0_80
-
Spark-ML-基于云平台和用户日志的
架构: 数据收集:spark stareming从Azure Queue收集数据,通过自定义的spark stareming receiver,源源不断的消费流式数据。 数据处理: spark stareming分析用户行为日志数据,通过实时的聚集,统计报
-
Spark-再接着上次的Lamda架构
日志分析 单机日志分析,适用于小数据量的。(最大10G),awk grep sort join等都是日志分析的利器。 例子: 1、shell得到Nginx日志中访问量最高的前十个IP cat access log 10 | awk & 039;(a[$1]++) E
-
地铁译:Sparkforpythonde
地铁译:Sparkforpythondevelopers---构建Spark批处理和流处理应用前的数据准备。
-
HDFSHighAvailability
HDFSHighAvailability体系介绍(UsingtheQuorumJournalManager)。HDFS集群中只有一个Namenode,这就会引入单点问题;即如果Namenode故障,那么这个集群将不可用,直到Namenode重启或者其他Namenode接入。
-
Presto常用语句整理
Presto常用语句整理。
-
Spark的三种分布式部署
Spark的三种分布式部署。目前Apache Spark支持三种分布式部署方式:分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1 0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势。
-
Task运行过程分析4——MapTask
Task运行过程分析4——MapTask内部实现2。在Task运行过程分析3——MapTask内部实现中,我们分析了MapTask的Collect阶段,并且解读了环形缓冲区使得MapTask的Collect阶段和Spill阶段可并行执行。。。接下来分析Spill阶段和Combine阶段
-
spark性能优化:数据倾斜调优
有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
-
Spark入门实战系列--4.Spark
lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码;
-
spark性能调优:开发调优
在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式 实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。
-
spark性能优化:shuffle调优
大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优。
-
Spark-再次分析Apache访问日志
Spark-再次分析Apache访问日志。对于访问日志简单分析grep等利器比较好,但是更复杂的查询就需要Spark了。
-
Spark-项目中分析日志的核心代码
Spark-项目中分析日志的核心代码
-
大数据学习笔记7·城市计算(1
众所周知,快速的城市化使得很多人的生活变得现代化,同时也产生了很多挑战,如交通拥挤、能源消耗和空气污染。

- 排行
- 热门