Oracle的多种复杂查询深入讲解
1、多表查询
1.1、简介
需要从多个数据表里取出数据,那么就属于多表查询,在FROM子句后面要设置多张数据表。
1.2、语法
SELECT [DISTINCT] * | 列名称 [别名],列名称 [别名],... FROM 表名称[别名],表名称[别名] [WHERE 过滤条件(s)] [ORDER BY 字段 [ASC | DESC],字段 [ASC | DESC],...];
1.3、实例
实例1、显示每个雇员的编号、姓名、职位、工资、部门名称、部门位置
SELECT e.empno,e.ename,e.job,e.sal,d.dame,d.loc FROM emp e, dept d WHERE e.deptno=d.deptno;
实例2、查询每个雇员的编号、姓名、职位、工资、工资等级、部门名称
SELECT e.empno,e.ename,e.job,e.sal,s.grade,d.dname FROM emp e,salgrade s,dept d WHERE e.sal BETWEEN losal AND hisal AND e.deptno=d.deptno;
1.4、表的连接方式
1.4.1 内连接
1、等值连接在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列
实例1、查询部门编号为30的员工编号、姓名、部门名称SELECT e.empno, e.ename, d.dname FROM emp e, dept d WHERE e.deptno = d.deptno and e.deptno = 30;2、非等值连接在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>
实例1、查询工资为1500以上的员工所属部门和所在的具体地点
SELECT DISTINCT d.dname, d.loc FROM emp e, dept d WHERE e.deptno = d.deptno and e.sal >1500;
3、自然连接
在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。简言之,基于两个表的同名的一个或多个列
【注意】自然连接是根据两个表中同名的列而进行连接的,当列不同名时,自然连接将失去意义
实例1、查询所有员工的员工编号、员工姓名、部门编号、部门名称
Select e.empno, e.ename, e.deptno, d.dname From emp e NATURAL JOIN dept d;
1.4.2 外连接
用于检索一个表的所有记录和另一个表中的匹配行。
(+)号的作用:+号可以理解为补充的意思,加在那个表的列上就代表这个表的列为补充。加在右表的列上代表右表为补充,为左连接。加在左表的列上代表左表为补充,为右连接。注意:完全外连接中不能使用+号。(+)为Oracle特有。
创建两张实验表
CREATE TABLE t_A ( id number, name VARCHAR2(10) ); CREATE TABLE t_B ( id number, name VARCHAR2(10) ); INSERT INTO t_A VALUES(1,'A'); INSERT INTO t_A VALUES(2,'B'); INSERT INTO t_A VALUES(3,'C'); INSERT INTO t_A VALUES(4,'D'); INSERT INTO t_A VALUES(5,'E'); INSERT INTO t_B VALUES(1,'AA'); INSERT INTO t_B VALUES(1,'BB'); INSERT INTO t_B VALUES(2,'CC'); INSERT INTO t_B VALUES(1,'DD'); INSERT INTO t_B VALUES(7,'GG');
1、左外连接
左外连接就是在结果中除了满足连接条件之外的行,还包括LEFT OUTER JOIN左侧表的所有行。
代码实现
SELECT * FROM t_a a,t_b b WHERE a.id=b.id(+);

2、右外连接
与左外连接同理,无限满足右表,即根据右表中数据去左表搜索,如果没有匹配数据,填入null
代码实现
SELECT * FROM t_a a,t_b b WHERE a.id(+)=b.id;

3、全连接
左右表都不加限制。即右外连接的结果为:左右表匹配的数据+左表没有匹配到的数据+右表没有匹配到的数据
代码实现
SELECT * FROM t_a a FULL JOIN t_b b on a.id=b.id;

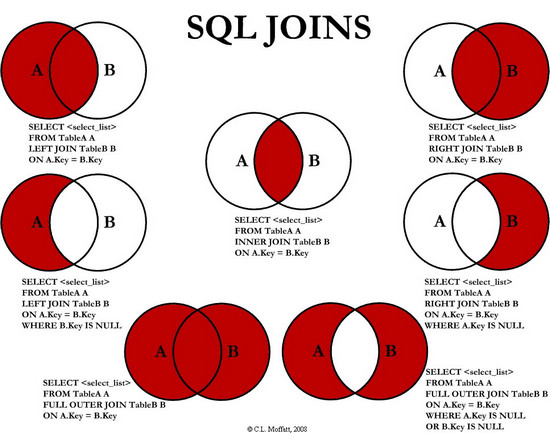
1.4.3 交叉连接
交叉连接不带WHERE子句,它返回被连接的两个表所有数据行的笛卡尔积,返回结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
实例1、求emp表和dept表的笛卡尔积
SELECT * FROM emp, dept;
1.4.4 自连接
自连接(self join)是SQL语句中经常要用的连接方式,使用自连接可以将自身表的一个镜像当作另一个表来对待,从而能够得到一些特殊的数据。
实例1、显示所有员工的上级领导的姓名
SELECT worker.ename, boss.ename FROM emp worker, emp boss WHERE worker.mgr = boss.empno;
2、统计查询
2.1、简介
需要使用统计函数的查询称为统计查询2.1.1 常用的统计函数
统计个数:COUNT(*|[DISTINCT]字段)、最值:(MAX(字段)、MIN(字段))、求和:SUM(数字字段)、求平均:AVG(数字字段)2.2、语法
SELECT [DISTINCT] 分组字段 [别名],... | 统计函数 FROM 表名称[别名] [WHERE 过滤条件(s)] [ORDER BY 字段 [ASC|DESC]];
2.3、实例
实例1、查询所有雇员之中最高和最低工资
SELECT MAX(sal),MIN(sal) FROM emp;
实例2、统计出所有雇员的总工资以及平均工资
SELECT SUM(sal),AVG(sal) FROM emp;
2.4、分组统计查询
2.4.1 语法SELECT [DISTINCT] 分组字段 [别名],... | 统计函数 FROM 表名称[别名] [WHERE 过滤条件(s)] [GROUP BY 分组字段,分组字段,分组字段,...] [ORDER BY 字段 [ASC|DESC]];
2.4.2 实例
实例1、按照职位分组,统计出每个职位的名称、人数、平均工资
SELECT job,COUNT(*),AVG(sal) FROM emp GROUP BY job;
实例2、查询每个部门的名称、人数、平均工资
SELECT d.dname,COUNT(e.empno),AVG(e.sal) FROM emp e,dept d WHERE e.deptno(+)=d.deptno GROUP BY d.dname;
实例3、查询出平均工资高于2000的职位名称以及平均工资。
SELECT job,AVG(sal) FROM emp GROUP BY job HAVING AVG(sal)>2000;
2.4.3关于WHERE与HAVING的区别
WHERE发生在GROUP BY操作之前,属于分组前的数据筛选,即:从所有的数据之中筛选出可以分组的数据,WHERE子句不允许使用统计函数;
HAVING发生在GROUP BY操作之后,是针对于分组后的数据进行筛选,HAVING子句可以使用统计函数;
3、子查询
3.1、简介
当一个查询是另一个查询的条件时,称之为子查询。3.2、语法
SELECT [DISTINCT] * | 列名称 [别名],列名称 [别名],... FROM 表名称[别名] [WHERE 过滤条件(SELECT [DISTINCT] * | 列名称 [别名],列名称 [别名],... FROM 表名称[别名] [WHERE 过滤条件(s)] )]
3.3、分类
单行子查询、多行子查询、多列子查询、做为from字句的子查询(内嵌视图查询)3.3.1单行子查询
单行子查询是指只返回一行数据的子查询语句实例显示与SMITH同部门的所有员工
SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename = 'SMITH');
3.3.2 多行子查询
多行子查询指返回多行数据的子查询实例查询和部门10的工作相同的雇员的名字、岗位、工资、部门号
SELECT ename, job, sal, deptno FROM emp WHERE job IN(SELECT DISTINCT job FROM emp WHERE deptno = 10);
1、在多行子查询中使用all操作符
实例显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
SELECT ename, sal, deptno FROM emp WHERE sal > ALL(SELECT sal FROM emp WHERE deptno = 30);方法二 使用聚合函数,(执行效率最高)
SELECT ename, sal, deptno FROM emp WHERE sal > (SELCT MAX(sal) FROM emp WHERE deptno = 30);
2、在多行子查询中使用any操作符
实例显示工资比部门30的任意一个员工的工资高的员工姓名、工资和部门号
SELECT ename, sal, deptno FROM emp WHERE sal > ANY (SELECT sal FROM emp WHERE deptno = 30);方法二使用聚合函数,(执行效率最高)
SELECT ename, sal, deptno FROM emp WHERE sal > (SELECT MIN(sal) FROM emp WHERE deptno = 30);
3.3.3 多列子查询
多列子查询是指查询返回多个列数据的子查询语句实例查询与SMITH 的部门和岗位完全相同的所有雇员
SELECT * FROM emp WHERE(deptno, job) =(SELECT deptno, job FROM emp WHERE ename='SMITH');
3.3.4内嵌视图查询查询
当在from子句中使用子查询时,该子查询会被作为一个视图来对待,因此叫做内嵌视图,当在from 子句中使用子查询时,必须给子查询指定别名(不能使用as关键字)实例 显示高于自己部门平均工资的员工的信息
SELECT e.ename, e.sal, e.deptno,temp.avgsal FROM emp e, (SELECT deptno, AVG(sal) avgsal FROM emp GROUP BY deptno) temp WHERE e.deptno = temp.deptno AND e.sal >temp.avgsal;
4、集合操作(交、并、差)
为了合并多个select语句的结果,可以使用集合操作符号union(并集),union all(与union相似,但是它不会取消重复行,而且不会排序),intersect(交集),minus(差集)。多用于数据量比较大的数据局库,运行速度快。实例1、 查询工资在2500以上或工作是经理的员工的姓名、工资、工作
SELECT ename, sal, job FROM emp WHERE sal >2500 UNION SELECT ename, sal, job ROM emp WHERE job = 'MANAGER';实例2、 查询工资在2500以上且工作是经理的员工的姓名、工资、工作
SELECT ename, sal, job FROM emp WHERE sal >2500 INTERSECT SELECT ename, sal, job ROM emp WHERE job = 'MANAGER';实例3、 查询工资在2500以上且工作不是经理的员工的姓名、工资、工作
SELECT ename, sal, job FROM emp WHERE sal >2500 MINUS SELECT ename, sal, job ROM emp WHERE job = 'MANAGER';
5、伪列
5.1、简介
伪列就像Oracle中的一个表列,但实际上它并未存储在表中。伪列可以从表中查询,但是不能插入、更新或删除它们的值。
常用的伪列:rowid和rownum。
5.2 、rowid
ROWID是一种数据类型,它使用基于64为编码的18个字符来唯一标识一条记录物理位置的一个ID,类似于Java中一个对象的哈希码,都是为了唯一标识对应对象的物理位置,需要注意的是ROWID虽然可以在表中进行查询,但是其值并未存储在表中,所以不支持增删改操作
实例一、 观察rowid 和 rownum
SELECT ROWNUM,ROWID,empno,ename,job FROM emp WHERE ROWNUM <= 5;

ROWID 的组成分析
|
数据对象编号 |
文件编号 |
块编号 |
行编号 |
|
OOOOOO |
FFF |
BBBBBB |
RRR |
可以用ROWID用来唯一标识表中数据(物理地址唯一)
应用 可以用来删除表中重复数据
DELETE FROM 表名 WHERE ROWID NOT IN( SELECT MIN(ROWID) FROM表名GROUP BY DEPTNO);
5.3、rownum
在查询的结果集中,ROWNUM为结果集中每一行标识一个行号,第一行返回1,第二行返回2,以此类推。通过ROWNUM伪列可以限制查询结果集中返回的行数。
ROWNUM与ROWID不同,ROWID是插入记录时生成,ROWNUM是查询数据时生成。ROWID标识的是行的物理地址。ROWNUM标识的是查询结果中的行的次序。
实例1、 查询前5名员工的姓名,工作,工资
SELECT ROWNUM rn,ename, job, sal FROM emp WHERE rn<=5;
实例2、查询5~10号员工的姓名,工作,工资
SELECT * FROM (SELECT ROWNUM rn, ename,job, sal FROM emp) WHERE rn > 5 AND rn <= 10;

-
 如何使用kali的Searchsploit查找软件漏洞
如何使用kali的Searchsploit查找软件漏洞
-
 iOS UITextField 使用详解
iOS UITextField 使用详解
-
 hibernate3中的hibernateDaoSupport到hibernate4中不适用的情况分析和解决
hibernate3中的hibernateDaoSupport到hibernate4中不适用的情况分析和解决
-
 又是七夕,1000元租个美女,50元租个私教的App靠谱吗?
又是七夕,1000元租个美女,50元租个私教的App靠谱吗?
- 文章
- 推荐
- 热门新闻